Deploying regex.help and CI/CD

Now that I've written up [how regex.help was built]({% post_url 2021-05-20-building-regex-help %}), it's time to focus on deployment. I used to think deployment was... not the most exciting part of building things. Howqever, recently I find it more and more interesting, probably because I care more about good CI/CD. Elixir and fly.io make it even cooler and shinier - let's jump in!
In my [last side project]({% post_url 2021-05-03-building-secretwords %}), I wanted to see how it feels deploying everything by hand. Turns out, it's fine - but not the most interesting thing to do. This sad, little script does most of the work, but then I still need to SSH into the server and restart. If I wanted to make it do everything, I'd probably end up with something similar to what David did here.
Also, starting a new project requires a bunch of manual setup and I wrote down the necessary steps here (for which BTW I have to thank Simon Willison, who's blowing the horn of writing documentation for personal projects). In the past, I atomated stuff like this with Ansible, but didn't get to doing it this time.
Fly
Which is just as well - because it made me look at other options and find fly.io. Fly is great - it takes your Dockerfile and magically makes it run on servers around the world, as close to your users as possible. So when you visit your site from Berlin, you'll get a response from the Frankfurt data center, but if you're in San Francisco, Sunnyvale, CA will probably handle it.
The way this happens is all pretty well-described in the Fly docs and their blog. While it initially only sounds good for stateless/DB-less apps, they actually have a great story for databases too (probably the thing I will play with next).
Also, it's the kind of place, where the founders respond to your support requests on the forum and HN legends retweet your tweets when you mention Fly - so that's nice.
Deployment
OK, enough with the fawning - how do you actually deploy this thing? As mentioned, you need a Dockerfile first. It can be pretty simple in the simplest cases - you can use the official elixir Docker image (try elixir:1.12) and serve your app using mix server. In my case the Dockerfile got a bit more involved, because I needed Rust and played with multi-stage builds a little. Fly also has a good example in their Elixir setup guide.
Once I had a working Dockerfile, following that guide didn't take very long and my app was live. That was neat - flyctl feels like a Heroku-like CLI tool and the process was generally smooth, including the custom domain setup and getting a TLS certificate.
At this point I could easily make changes to the app and deploy using fly deploy. Time to move on to...
Continuous Integration
Of course, I didn't want to stop there - the code should get tested and deployed automatically of everything passes on every merge to the main branch. Basically, the workflow I wanted was:
- on every push to the main repository,
- run automated checks (formatting, style check using credo, unit tests),
- if that passes, spin up a a QA environment and deploy the new version there,
- run end-to-end functional tests (using RainforestQA - where I work on building the automation product - dogfooding!),
- if they pass, deploy to production and spin down QA.
Is that an overkill for a hobby app? Yes! Probably! Maybe! It's fun, though! And in all seriousness, I think this kind of setup it's worth it for most projects. If your app is small, it's realistic to set up end-to-end test every single feature on every single release, which is just awesome. As it grows, as long as you can write your tests as you add new stuff, you'll continue chugging along happily.
The final pipeline, which I set up on Github Actions, looks like below and here's the YAML file defining it.
There are a couple of interesting things going on here, so let's go through the file job-by-job.
Automated (formatting/style/unit) tests
The first stage, hepfully called unit-test, is running the automated checks - it makes sense to run these first, since they're fast and effectively free. If any of them fails, there's no point going further.
Since we've got a Dockerfile, we ideally want to build and test with it. There are, however, some complications:
- We have dev-only dependencies, like e.g. credo, which we don't need in production - they're defined as
only: :testinmix.exs. Installing them in production is not the end of the world, but we should try to avoid it. - Similarly, there are files, like helper scripts and code formatter configs, which we don't need in production.
Luckily, both of these can be solved using Docker multi-stage builds. We define the first stage, our builder, to have all the things we need to build our app: Erlang, Elixir, Rust etc. and we run with it all the way until installing (pro only!) dependencies.
Then we take a little pause and define our "testing" stage of the Dockerfile. In it, we copy over a couple more files and install all dependencies, including non-prod. We also configure the test stage to end by running the tests. Then, in our CI config, we basically just say "build and run the test stage" which will result in only doing what's necessary here and skipping the rest of the Dockerfile.
Similarly, we can define the production/app stage with just the bare minimums: compile files of out app an a handful of packages needed to run everything. We don't even need Elixir at this point, since the app has been compiled down to Erlang!
Scaling up and deploying to QA
Assuming our automated tests passed, we want to move on to end-to-end functional tests. We could just deploy to production, test there and revert if anything's wrong, but we can do better than that. One of the advantages of using a host like Fly is that we can easily create apps as well as scale them up/down.
Since fly published their GitHub Action it's pretty easy to hook up: use the superfly/flyctl-actions@1.1 action and pass in scale/deploy as arguments, passing in the appropriate config files, and you're done... in theory. In practice, I found that running scale count 1 when your app is scaled down to 0 sometimes does nothing without returning an error. I ened up solving this problem in a very sophisticated way: running the command twice. Since it's indepotent, it doesn't matter and it seems to do the trick.
Another thing worth mentioning is that this whole workflow assumes there's only a single PR being worked on at a time and thus we only have a single QA environment. If there were many copies of me working on different features at the same time, I'd probably use the Fly GraphQL API to create QA environments dynamically. But let's keep it simple!
Running Rainforest tests
Now comes the exciting stuff: running end-to-end tests to make sure our app actually works as intended. Since I've built a decent chunk of our automation product at Rainforest, I'm going to use that.
I've set up a couple short tests to verify the functionality; here's how the test looks like
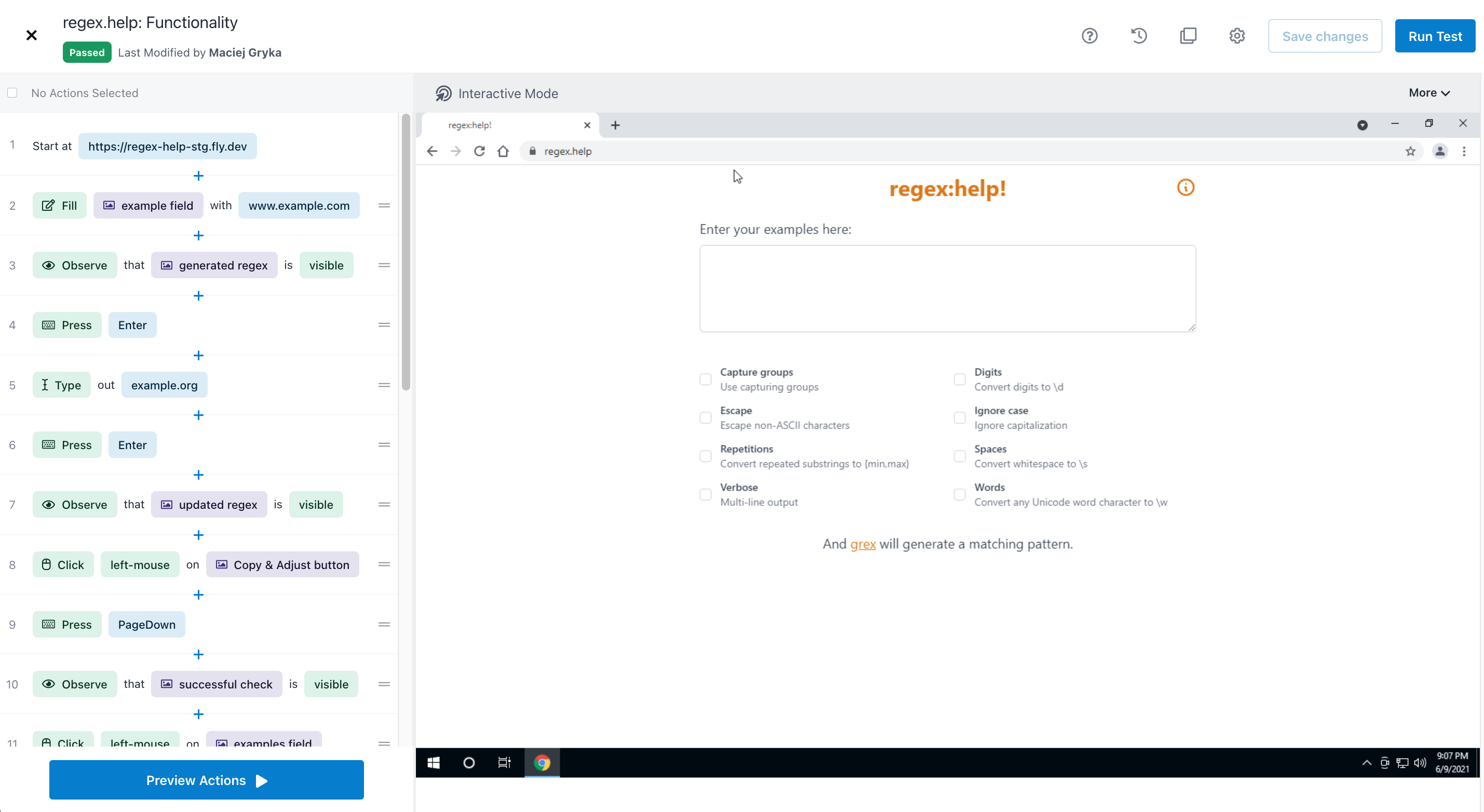
And here's a video of a run-through, which Rainforest records as it's testing.
Production deployment
Finally, after all the build steps above pass, we can deploy to production. This is the same as deploying to QA earlier on, only now we use a different config file.
We can also spin down the QA environment to avoid using resources unnecessarily.
Conclusion
And that brings us to the end of our journey: we now have a working Elixir app, backed by a Rust package, running all over the world and auto-dedploying with a decent CI/CD pipeline. That's not to be sneezed at.
Let me know what you think on Twitter and whether you found this useful.